在视频监控、工业巡检以及边缘计算等场景中,常见的一个现实问题是协议割裂:前端设备通常通过RTSP推流,而浏览器原生并不支持直接播放RTSP。这就带来了一个工程上的关键挑战——如何在不引入高延迟和复杂转码的前提下,将设备侧的视频流高效地分发到浏览器端。
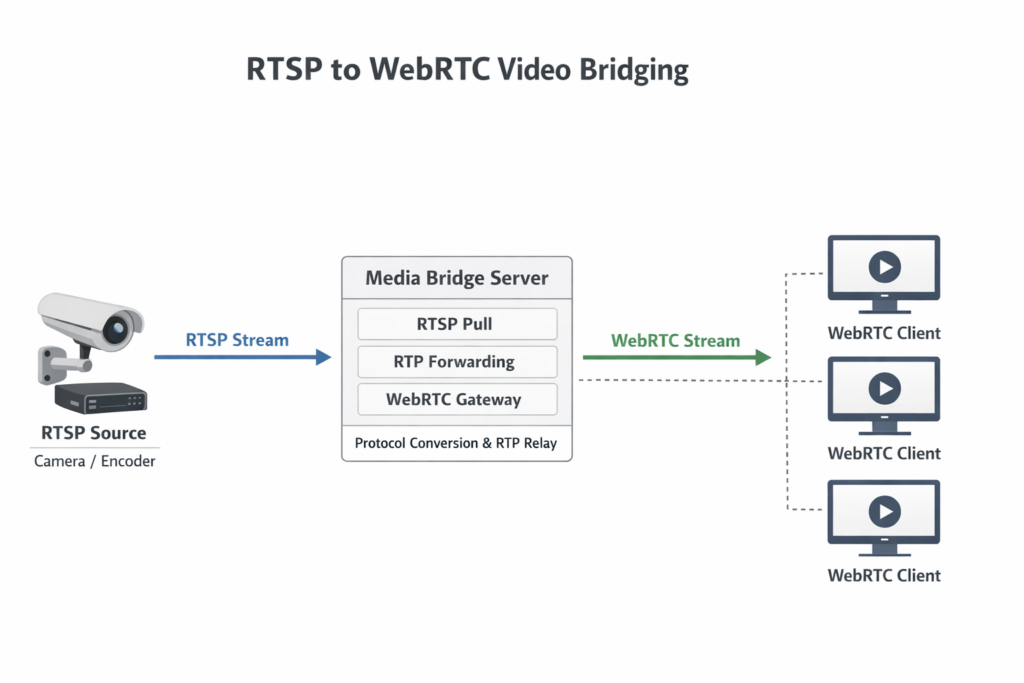
一种更直接且高效的思路,是利用WebRTC作为浏览器侧的实时传输协议,同时在服务端完成协议层的桥接,将RTSP流转换为WebRTC可消费的RTP数据流。这种方式避免了传统转码链路(例如FFMPEG+纯接口转发 )带来的性能损耗,同时保留了实时性的优势。
通过golang程序实现一个典型的视频桥接架构:上游通过RTSP拉流(通常来自摄像头或推流工具),服务端将RTP包转发到WebRTC PeerConnection,下游浏览器通过 WebRTC 实时播放视频。整体链路为:RTSP → RTP → Go服务 → WebRTC → 浏览器。
零、在本机启一个mediamtx作为RTSP服务端,再通过ffmpeg把本机摄像头推流到服务器来模拟摄像头的RTSP流
./mediamtx &./ffmpeg -f v4l2 -i /dev/video0 \
-vcodec libx264 -preset veryfast -tune zerolatency \
-f rtsp -rtsp_transport tcp \
rtsp://test:123456@127.0.0.1:8554/test一、golang程序入口main中首先确定RTSP地址,并开一个Gin HTTP服务,同时维护一个clients映射,用于保存每个WebRTC客户端对应的Track:
每个客户端并不是单独拉流,而是共享同一 RTSP输入流,服务端通过fan-out(扇出)机制将RTP包写入多个WebRTC Track,从而实现“一路输入,多路输出”
import (
"github.com/bluenviron/gortsplib/v5"
"github.com/bluenviron/gortsplib/v5/pkg/base"
"github.com/bluenviron/gortsplib/v5/pkg/description"
"github.com/bluenviron/gortsplib/v5/pkg/format"
"github.com/gin-gonic/gin"
"github.com/pion/rtp"
"github.com/pion/webrtc/v3"
)
rtspURL := os.Getenv("RTSP_URL")
if rtspURL == "" {
rtspURL = "rtsp://test:123456@127.0.0.1:8554/test"
}
var clientsMu sync.Mutex
clients := map[string]*webrtc.TrackLocalStaticRTP{}二、HTTP部分分为三个路由:
1)“/”路由返回播放器页面
前端页面核心逻辑如下:
浏览器创建RTCPeerConnection → 生成Offer(SDP)→ 发送给服务端 → 服务端生成Answer → 浏览器设置远端描述。需要注意的是,这里没有使用STUN/TURN(iceServers 为空),意味着该方案默认运行在内网或可直连环境,否则无法穿透NAT。
pc=new RTCPeerConnection({iceServers:[]});
pc.addTransceiver('video',{direction:'recvonly'});
const offer=await pc.createOffer();
await pc.setLocalDescription(offer);
const resp=await fetch('/offer',{
method:'POST',
headers:{'Content-Type':'application/json'},
body:JSON.stringify({sdp:offer.sdp,type:offer.type})
});
const answer=await resp.json();
await pc.setRemoteDescription({type:answer.type,sdp:answer.sdp});服务端“/offer”路由处理逻辑是WebRTC的核心:
这里做了两件关键事情:
m := webrtc.MediaEngine{}
_ = m.RegisterCodec(webrtc.RTPCodecParameters{
RTPCodecCapability: webrtc.RTPCodecCapability{
MimeType: webrtc.MimeTypeH264,
ClockRate: 90000,
SDPFmtpLine: "packetization-mode=1;profile-level-id=42e01f",
},
PayloadType: 96,
}, webrtc.RTPCodecTypeVideo)
api := webrtc.NewAPI(webrtc.WithMediaEngine(&m))
pc, _ := api.NewPeerConnection(webrtc.Configuration{})创建Track,并绑定到PeerConnection:
Track是WebRTC中媒体发送的抽象,本质上是RTP流的出口。这里使用TrackLocalStaticRTP,意味着可以手动写入RTP包
track, _ := webrtc.NewTrackLocalStaticRTP(
webrtc.RTPCodecCapability{
MimeType: webrtc.MimeTypeH264,
ClockRate: 90000,
},
"video", "pion",
)
pc.AddTrack(track)信令交换部分:
接收浏览器Offer → 设置远端 SDP → 生成 Answer → 返回给浏览器。GatheringCompletePromise用于等待ICE candidate收集完成,否则SDP不完整。
offer := webrtc.SessionDescription{Type: webrtc.SDPTypeOffer, SDP: req.SDP}
pc.SetRemoteDescription(offer)
ans, _ := pc.CreateAnswer(nil)
pc.SetLocalDescription(ans)
<-webrtc.GatheringCompletePromise(pc)将Track存入clients,用于后续RTP分发:
这里通过DESCRIBE + SETUP建立RTSP会话,并解析媒体格式(H264/H265)。
clientsMu.Lock()
clients[c.ClientIP()+"_"+time.Now().Format("150405")] = track
clientsMu.Unlock()核心转发逻辑在OnPacketRTP:
RTSP → 解复用 → 得到RTP包 → 广播写入所有WebRTC Track
cli.OnPacketRTP(media, formaH264, func(pkt *rtp.Packet) {
clientsMu.Lock()
totalBytes += uint64(len(pkt.Payload))
totalPackets++
activeClients := make([]*webrtc.TrackLocalStaticRTP, 0, len(clients))
for _, t := range clients {
activeClients = append(activeClients, t)
}
clientsMu.Unlock()
for _, t := range activeClients {
t.WriteRTP(pkt)
}
})统计接口“/stats”路由通过简单计数实现码率计算:
前端每秒拉取一次,实现实时监控。
kbps := uint64(float64(totalBytes*8) / 1024 / duration)
pktps := uint64(float64(totalPackets) / duration)第一,WebRTC并不负责“获取视频”,它只负责“传输媒体流”。视频源可以来自 RTSP、文件、摄像头等。
第二,WebRTC的关键不是API,而是:
第三,这种架构属于典型的“边缘网关模式”:
RTSP(设备侧协议) → WebRTC(浏览器协议)
在工业监控、视频巡检、边缘计算中非常常见